
데이터 중심 머신러닝 시스템 개발을 위한 AI 데이터 플랫폼 활용
●
●
●
* 본 내용은 박영진 본부장(☎ 02-6954-2960, youngjin.park@crowdworks.kr)에게 문의하시기 바랍니다.
** 본 내용은 필자의 주관적인 의견이며 IITP의 공식적인 입장이 아님을 밝힙니다.
인공지능이 전 산업 분야로 확산하면서 머신러닝을 통해 여러 가지 제품이나 서비스에 인공지능을 활용하게 되었다. 머신러닝은 컴퓨터 시스템과 프로그램이 인간의 직접적인 도움이나 개입 없이 인간의 인지 과정과 유사한 방식으로 문제를 해결하기 위해 학습한 예측 결과를 활용하는 것으로서 “코드로서 명령하지 않은 동작을 데이터로 학습하고 기계가 실행하도록 알고리즘을 개발하거나 연구하는 분야”로 정의할 수 있으며[1], 지도 학습, 비지도학습, 강화학습으로 분류할 수 있다. 머신러닝은 방대한 데이터를 처리하고 특정 작업을 수행하기 위한 패턴을 인식하도록 훈련되며, 인간과 마찬가지로 더 많은 학습을 통해 인공지능이 수행해야 하는 임무(task)를 더 잘 할 수 있게 된다. 따라서 특정한 임무를 수행할 수 있도록 인공지능을 훈련시키기 위해서는 수행할 임무에 대한 훈련을 위해서 지도학습 관점에서 인공지능 학습용 데이터가 필요하다. 고품질의 인공지능 학습용 데이터는 머신러닝의 성능을 향상시키는데 핵심적인 요소이다. 분류와 회귀 같은 지도 학습이나 추천 시스템에서 높은 성능을 내려면 정답 정보가 포함된 데이터나 말뭉치, 사전처럼 양질의 학습용 데이터가 많이 필요하다[2]. 이미지 인식, 음성 인식, 기계 번역 등 다양한 분야에서 인공지능에서 성과를 거두게 된 것은 인공지능 알고리즘의 발전과 이를 뒷받침하는 컴퓨팅 리소스 등으로 가능해졌지만 무엇보다 대량의 인공지능 학습용 데이터셋이 있어서 가능했던 일이기도 하다. 그런데, 인공지능 연구 개발 과정에서 주요 병목 현상은 더 이상 알고리즘이나 하드웨어에서 발생하지 않고 의미 있는 작업을 해결하기 위해 충분한 인공지능 학습용 데이터셋을 만드는 것에서 발생하고 있다[3].
II. 머신러닝 모델 생애주기
일반적인 머신러닝 모델의 생애주기는 [그림 1]과 같이 계획→구축(수집+저장+가공)→활용(유통)→계획에 다시 반영되는 순환 구조로 이루어진다.
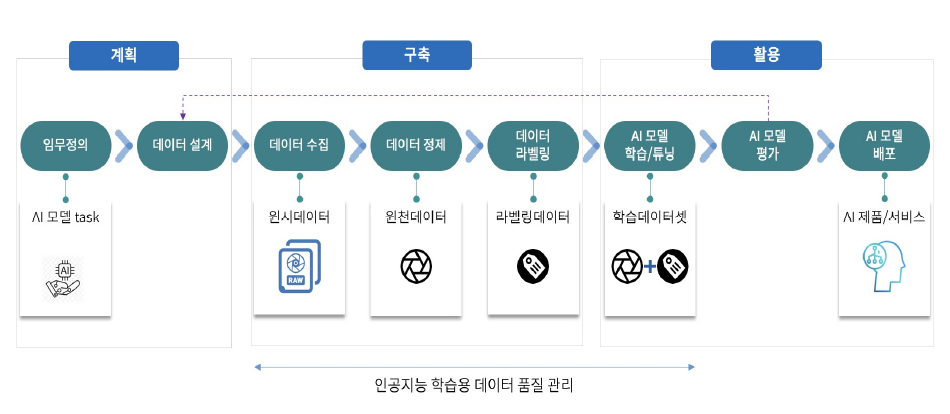
<자료> 박영진, “인공지능 학습용 데이터 플랫폼 연구”, 한국통신학회지, 정보와통신, 39(11), 2022, 23-29.
[그림 1] 머신러닝 모델 생애주기
인공지능을 통해서 해결하고자 하는 비즈니스 문제를 명확하게 이해하고 문제를 해결하기 위한 가설을 수립하고 머신러닝 모델의 목표를 설정한다. 머신러닝은 기술 부채 중 이자율이 가장 높은 신용카드와 같아서[4] 모든 문제를 머신러닝으로 해결할 것이 아니라, 머신러닝을 통한 해결책이 다른 대안에 비해 소요되는 리소스나 필요한 시간 등을 고려해서 효과적일 때 선택해야 한다. 무엇보다 머신러닝 모델을 위해 학습용 데이터가 확보 가능한지 확인이 필요하다. 이를 위해 샘플 데이터에 대한 수집과 분석을 진행하여 어떤 데이터가 필요하고, 어떤 데이터를 수집해야 하는지 파악할 수 있으며, 데이터의 특성을 분석하여 머신러닝 모델에 적합한 특성(feature)을 결정할 수 있다.
2. 데이터 설계머신러닝 모델을 어떤 목적으로 사용할지에 따라 어떤 데이터를 수집하고 어떻게 라벨링 할 지 정의해야 한다. 수집한 데이터가 어떤 종류인지 그리고 머신러닝 모델에 따라 데이터의 전처리(preprocessing)와 데이터 어노테이션 방법이 달라진다. 학습용 데이터의 양은 머신러닝 모델의 성능에 많은 영향을 주기 때문에 충분한 양의 데이터를 수집해야 머신러닝 모델의 성능을 높일 수 있다. 따라서, 데이터가 수집이나 획득이 가능한지, 법적인 문제는 없는지 사전 검토가 필요하고 데이터 획득/수집, 데이터 정제, 데이터 가공 각 단계별로 원시 데이터(데이터 획득/수집 결과물), 원천 데이터(데이터 정제 결과물), 라벨링 데이터(데이터 가공 결과물) 별로 데이터 포맷, 수량, 유형 등을 정의해야 한다.
3. 데이터 수집인공지능 서비스나 시스템의 성능은 충분한 량의 우수한 품질의 학습용 데이터에 많은 영향을 받으며, 머신러닝 모델에 가장 부합하는 데이터 소스가 무엇인지 어떻게 수집/획득할지 결정해야 한다. 데이터 수집 및 획득의 경우 데이터 소스에 따라서 공개 데이터 사용, 내부 데이터 소싱(sourcing), 외부 데이터 소싱 등의 방식으로 구분할 수 있으며, 데이터 수집 및 획득 방안으로는 데이터 구매, 데이터 제작, 합성 데이터(synthetic data)1) 활용 등이 있다. 데이터 수집 시 법, 제도적 규정을 준수하고 지적재산권, 초상권, 음성권 등의 각종 사용 권리 확보해야 하며, 실제 환경을 최대한 반영할 수 있는 데이터의 통계적 다양성을 확보할 수 있어야 하고 머신러닝 모델이 비윤리 또는 편견을 학습하지 않도록 데이터 편향 방지 및 데이터 윤리 준수를 해야 한다.
4. 데이터 정제수집된 데이터를 분석하고 가공하여 머신러닝 모델 학습에 적합한 형식으로 전처리를 하는 과정으로 머신러닝 모델의 성능과 정확도에 큰 영향을 미치는 과정이다. 데이터셋에 결측값이 있을 경우 해당 값에 대한 대체값을 찾아 채워주는 결측값 처리, 데이터셋에서 이상치(outlier)를 찾아내고 이를 제거하거나 대체값으로 채워주는 이상치 처리, 데이터의 스케일 차이를 줄이기 위해 각 특성의 값을 일정 범위로 조정하는 정규화 등이 있다. 또한, 데이터 정제 단계에서 개인 식별 정보를 삭제하거나 식별할 수 없도록 기술적 기법을 적용하여(예; 이미지에 포함된 개인 얼굴이나 차량 번호 블러(blur) 처리 등) 개인정보를 보호하는 데이터 비식별화를 수행하게 된다. 개인정보 비식별화는 개인정보 보호법에 따른 규제를 준수하기 위한 필수적인 절차 중 하나이며, 개인정보 유출을 방지하고 데이터를 활용할 수 있도록 하는 기본적인 작업이다.
5. 데이터 라벨링데이터 라벨링(data labeling)은 머신러닝 모델 학습을 위해 데이터에 대한 정답(label)을 부여하는 작업으로서, 안면 인식이나 이메일 스팸 분류 시스템 등에 기계 학습 모델을 적용하기 위해서는 얼굴 이미지에 이름 등이 레이블되어 있거나 이메일에 스팸 여부 등이 레이블 되어 있는 기계 학습용 데이터셋이 필요하며, 머신러닝 모델의 학습 전에 데이터에 특정 값을 부여해 주는 것을 데이터 라벨링이라고 한다[5]. 머신러닝 모델 학습용 데이터셋에 대한 추가적인 정보를 제공하기 위한 작업으로서 사람이 이해할 수 있는 형태로 제공되며, 객체의 바운딩 박스(bounding box)나 세그먼트(segment)와 같은 객체의 위치, 크기 및 형태와 관련된 정보를 제공하여 이미지 객체 인식을 위한 모델 학습에 사용하게 된다. 데이터 라벨링 작업은 이미지, 영상, 텍스트, 사운드 등의 원시 데이터에 작업자들이 데이터 가공 도구(annotation tool)를 활용하여 인공지능 학습에 필요한 다양한 정보를 목적에 맞게 입력하는 것으로서 데이터 유형과 머신러닝 모델에 따라 폴리곤, 랜드마크, 키포인트, 태깅, 전사 등과 같이 다양한 데이터 라벨링이 이루어진다.
6. 모델 학습/튜닝라벨링 데이터를 사용하여 머신러닝 모델을 학습하게 되며, 모델 구조를 정의하고, 모델 학습 알고리즘을 선택하며, 입력 데이터와 해당 출력을 제공하여 모델의 가중치 및 파라미터(parameter)를 조정하는 학습 과정을 통해 모델은 학습 데이터에서 패턴과 관계를 찾고, 새로운 데이터에 대한 예측을 수행할 수 있는 일반화된 모델을 만들게 된다. 이후 모델의 하이퍼파라미터(hyperparameter) 값을 조정하여 모델의 성능을 최적화하는 모델 튜닝 과정을 거치며, 학습률, 배치 크기, 에포크 수 등과 같은 모델의 학습 프로세스를 제어하는 매개변수인 하이퍼파라미터 값을 변경하여 모델의 성능을 개선한다.
7. 모델 평가학습된 머신러닝 모델의 성능을 평가하게 되며, 모델의 정확도, 정밀도, 재현율 등의 성능지표를 통해 모델을 평가한다. 평가 결과에 따라서 머신러닝 모델을 다시 학습하거나 튜닝하고 필요하면 학습용 데이터셋 설계를 변경하여 새로운 학습용 데이터셋으로 재구축하여 머신러닝 모델 학습과 튜닝을 수행한다.
8. 배포 및 모니터링
머신러닝 모델이 적용될 환경에 맞게 모델을 배포하고, 유지보수를 진행하며, 모델을 모니터링하고, 문제가 발생하면 적시에 조치한다. 모델을 개발하고 운영하는 과정에서 정기적으로 모델의 성능을 평가하고 모니터링하는 것이 필요하며, 새로운 데이터가 수집되거나 모델성능 개선 등이 필요한 경우 모델 튜닝과 모델 재학습이 요구될 수 있다.
모든 단계들은 머신 러닝 모델 생애주기에서 반복적으로 수행하게 된다. 이와 같이 머신러닝 모델을 개발하고, 배포하고, 운영하며, 유지 보수하는 순환적인 운영 프로세스를 MLOps(Machine Learning Operations)라고 한다. 소프트웨어 개발의 DevOps와 유사한 개념으로, 머신 러닝 모델의 성능을 유지하기 위해서는 개발 과정뿐만 아니라 배포 및 운영 과정에서도 지속적인 관리와 개선이 필요하다. MLOps는 크게 데이터 측면과 모델 측면으로 구분할 수 있다. 데이터 처리 과정에서 데이터가 누락되거나 잘못된 데이터가 들어올 경우, 이를 식별하고 수정하게 되며, 모델 학습 과정에서 하이퍼파라미터를 조정하거나 모델 구조를 변경하는 작업을 수행할 수 있고 모델의 성능을 모니터링하여 필요한 경우 모델을 업데이트 하는 작업을 수행하게 되며, 이러한 작업들은 MLOps를 통해 자동화하거나 관리할 수 있다([그림 2] 참조).
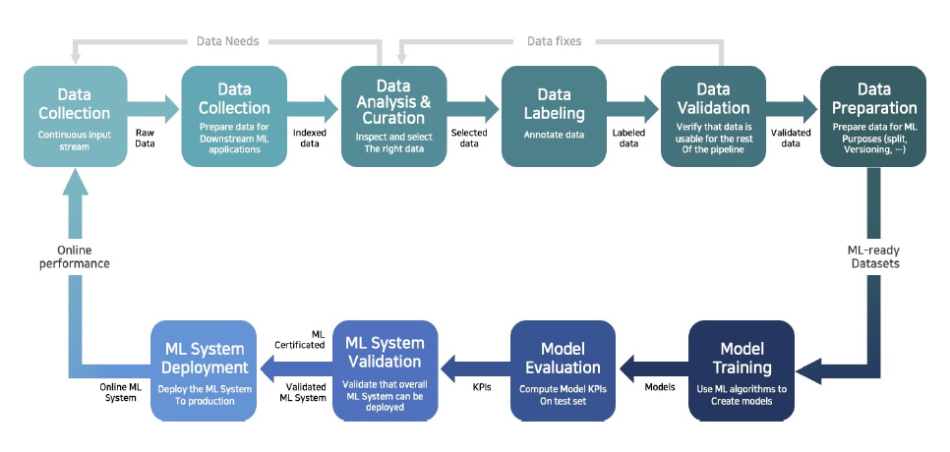
<자료> hKreuzberger, D., Kühl, N., & Hirschl, S. 2023, Machine learning operations(mlops): Overview, definition and architecture, IEEE Access. 재구성
[그림 2] MLOps 사이클
- 1)의료 정보, 국방 무기 체계 등과 같이 직접 확보하기 어려운 데이터로서 실제 데이터(real data)와 유사한 데이터를 컴퓨터 시뮬레이션이나 알고리즘 등을 통해 생성하는 데이터
III. 데이터 중심 AI
많은 머신러닝 모델은 시간이 지남에 따라서 성능이 저하되는 현상이 발생하는데, 모델이 처리하는 데이터와 환경이 동일해야 하지만 입력되는 데이터가 변경되거나 입력 변수와 출력 변수 간의 관계, 모델이 학습용 데이터셋에 과적합(overfitting)되어 있거나 데이터셋이 너무 적거나 또는 모델 구조, 하이퍼파라미터 설정 등의 다양한 요인에 의해서 발생한다[6]. 무엇보다 머신러닝 모델에 대한 알고리즘 연구개발 시점에는 고정된 범위 내의 정제된 데이터를 사용하는 반면, 실제 인공지능 서비스 운영 시 유입되는 데이터는 외부의 환경적인 요소로 패턴이 변할 수도 있으며, 모델을 개발할 때 사용된 데이터와 운영환경에서 사용되는 데이터의 분포가 다를 수 있다. 또한, 운영환경에서 사용되는 데이터는 노이즈가 포함될 가능성이 높으며, 이러한 노이즈는 모델의 성능을 떨어뜨리는 원인이 된다.
실제 AI 시스템은 인공지능 알고리즘인 코드와 데이터로 구성되어 있다. 따라서 AI 시스템의 성능 개선도 코드 중심인지 데이터 중심인지에 따라 나누어 볼 수 있다. 대부분의 AI 연구자들은 모델 관점에서 성능 개선을 위해서 머신러닝 모델에 필요한 특성을 선택하거나 추출하여 모델의 복잡성을 줄이고, 이를 통해 불필요한 정보를 제거하고, 모델이 핵심적인 특성을 잘 학습할 수 있도록 하여 성능을 개선하며 또한, 적절한 하이퍼파라미터를 찾아서 튜닝하기도 하며, 여러 개의 머신러닝 모델을 조합하는 앙상블 기법 등을 통해 더 나은 성능을 내는 모델을 만들기도 한다.
지난 2021년 3월, 스탠포드 대학교 교수였고 딥러닝 AI 대표이면서 머신러닝 분야에서 세계적으로 유명한 인공지능 연구자인 앤드류 응(Andrew NG)은 “머신러닝 시스템 개발: 모델 중심에서 데이터 중심으로”(A Chat with Andrew on MLOps: From Model-centric to Data-centric AI)라는 세미나를 통해 AI 모델 연구에 집중되어 있던 인공지능 분야에 앞으로 모델 중심이 아닌 데이터 중심으로 발전해 나가야 한다고 하는 데이터 중심 AI(Data centric AI)라는 새로운 방향을 제시하였다[7].
머신러닝 모델 개발 시 데이터의 획득, 정제 및 가공 등의 학습용 데이터 구축을 위해 전체 리소스의 80%를 사용하고 실제 머신러닝 모델 개발에 20%가 사용된다[8]]. 실질적으로 AI 시스템의 성능을 높이는 것은 코드의 대한 개선보다는 데이터에 대한 개선이 더 효율적이기 때문에 코드에 초점을 맞추는 대신 신뢰성, 효율성, 체계적인 방식으로 데이터를 개선하기 위한 시스템 기반 엔지니어링 프랙티스를 개발하는 데 주력하는 데이터 중심 접근법으로 이행해야 한다[7]. 데이터 관점에서 성능을 높이기 위해서는 데이터의 품질을 높이고 수량을 늘려야 한다. 데이터가 많으면 노이즈가 포함되어 있어도 모델 성능에 큰 영향을 미치지 못하고, 데이터가 적으면 데이터 일관성과 데이터 품질 모두 모델 성능에 큰 영향을 미친다. 따라서, 데이터 관점에서 성능을 높이기 위해서는 충분히 많은 양의 데이터를 수집하고 수집된 데이터에 일관성 있는 작업과 품질을 유지하여 데이터 라벨링이 이루어져야 한다.
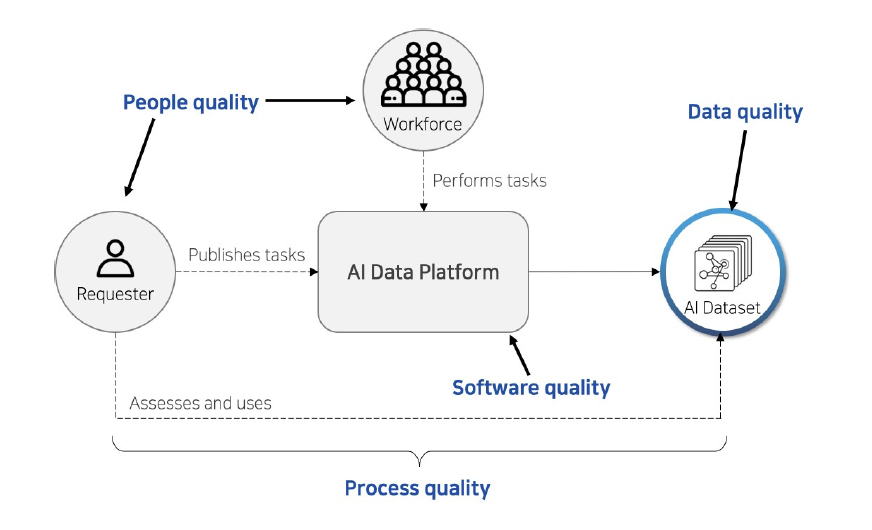
<자료> Daniel, F., Kucherbaev, P., Cappiello, C., Benatallah, B., & Allahbakhsh, M. 2018., Quality control in crowdsourcing: A survey of quality attributes, assessment techniques and assurance actions, ACM Computing Surveys(CSUR), 51(1), 1-40. 재구성
[그림 3] 인공지능 학습용 데이터 품질 요인
데이터 관점에서 성능을 높이기 위해 필요한 학습용 데이터 품질은 데이터 라벨링의 정확도, 라벨링의 일관성, 객체 다양성 등으로 이루어지는데 여기에 영향을 주는 것이 [그림 3]과 같이 인력(관리자, 작업자)의 품질, 작업 프로세스의 품질, 데이터 플랫폼의 품질 등이 있다[9]. 데이터 라벨링 프로세스 품질은 데이터 수집, 데이터 정제, 데이터 라벨링 등 데이터 라벨링 과정에서 데이터 품질을 보장하기 위해 품질관리 관점에서 프로세스를 수행하는지 모니터링하고, 발견된 문제점을 보완한다. 작업 관리자의 경우 학습용 데이터셋의 작업 기준과 방식에 대해 얼마나 이해하고 있는지가 품질에 영향을 미치며, 라벨링 데이터의 품질에 직접적인 영향을 미치는 작업자들을 관리하기 위해 작업의 정확도, 작업자의 성실성 등을 플랫폼을 통해 측정하고 이 결과를 작업자 선발 및 운영에 반영한다.
Ⅳ. AI 데이터 플랫폼
데이터 라벨링은 전형적인 HITL(Human In The Loop) 작업으로서 데이터의 품질을 개선하는데 사람의 피드백을 이용한다. 데이터 전처리나 일부 데이터 가공을 제외하고 대부분 사람에 의해 수동으로 작업이 이루어지며, 데이터 라벨링을 위한 작업자를 확보하여 데이터 가공을 하면 된다. 하지만, 데이터 라벨링은 단순하지 않으며, 데이터 라벨링 작업을 하는 데이터 라벨러에 대한 교육, 데이터 라벨링 작업 검수, 데이터 라벨링 작업 성과 분석, 데이터 라벨러 성과 분석 등 매우 복잡하고 다양한 작업이 포함되어 있다. 일관성 있고 정확한 고품질의 인공지능 학습용 데이터 파이프라인을 지원하기 위해서는 다음과 같은 기능으로 구성된 AI 데이터 플랫폼이 필요하다([그림 4] 참조).
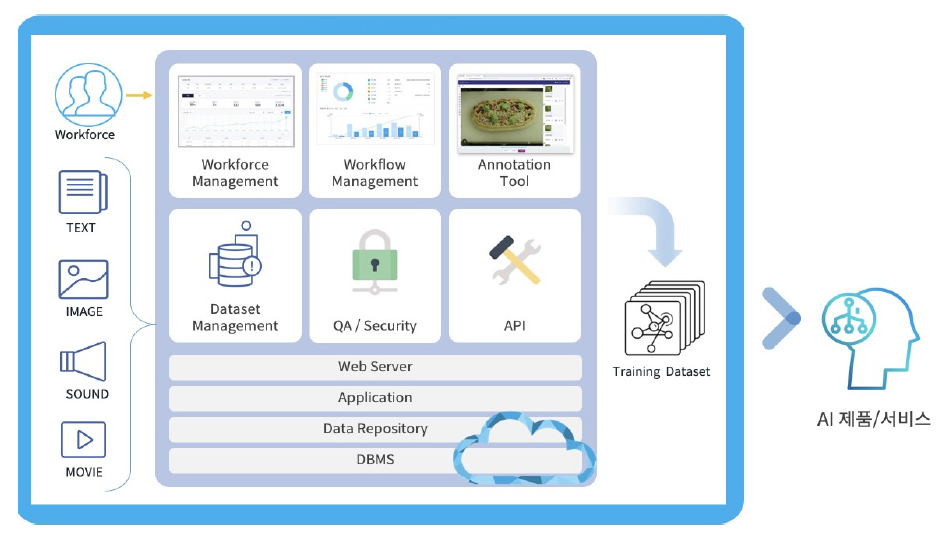
<자료> 박영진, “인공지능 학습용 데이터 플랫폼 연구”, 한국통신학회지, 정보와통신, 39(11), 2022. 23-29.
[그림 4] AI 데이터 플랫폼
데이터 라벨러는 머신러닝 모델을 훈련시키기 위해 필요한 인공지능 학습용 데이터셋에 라벨을 지정하는 작업을 수행한다. 데이터 라벨링은 머신러닝 모델의 품질과 성능에 직접적 인 영향을 미치므로, 데이터 라벨러는 데이터의 신뢰성과 일관성을 보장해야 한다. 데이터 라벨러는 정규직 또는 계약직 직원이나 외부 아웃소싱 그리고 일반 대중을 활용한 크라우드 소싱으로 나누어진다. 관련 도메인 전문성이 보장되어야 하는 경우 투입되는 데이터 라벨러는 학습용 데이터가 필요한 조직 내에 포함된 인력으로 수행하게 되며, 산업 도메인 지식이 필요 없거나 복잡도가 낮은 경우 등에서는 크라우드소싱으로 데이터 라벨러를 확보한다. 데이터 설계에 맞춰 필요한 작업 방식을 수립하고 이에 맞는 적절한 작업자 요건을 정의하고, 특정 도메인 지식이나 전문성이 필요한 경우(예; 번역, 헬스케어 등) 해당 전문 인력을 모집하며, 모집한 작업자 중에서 과거 프로젝트 수행 경험을 기준으로 인력을 선발하여 투입한다. 또한, 데이터 라벨러에 대한 훈련과 교육을 통해 일관된 품질과 정확도를 유지할 수 있도록 한다. 데이터 라벨링의 경우 학습용 데이터에 노이즈가 포함되지 않도록 데이터 한건 한건에 대한 작업이 정확하고 일관되어야 하기 때문에 관리 도구를 통해 라벨링 작업을 추적하고, 라벨러들의 성과와 품질을 모니터링한다.
2. 데이터 작업 프로세스 관리(Workflow Management)데이터 작업 프로세스는 [그림 5]와 같은 순서로 이루어진다.
- 분석: 데이터 요구사항을 수립하고 이를 기준으로 데이터 수집 및 가공 방안을 수립하며, 데이터셋 구조를 정의한다.
- 설계: 머신러닝 모델에 필요한 데이터 종류, 수량, 라벨링 방식 등에 대해서 요구사항에 맞춰 설계하고, 작업에 필요한 인력의 요건을 정의한다.
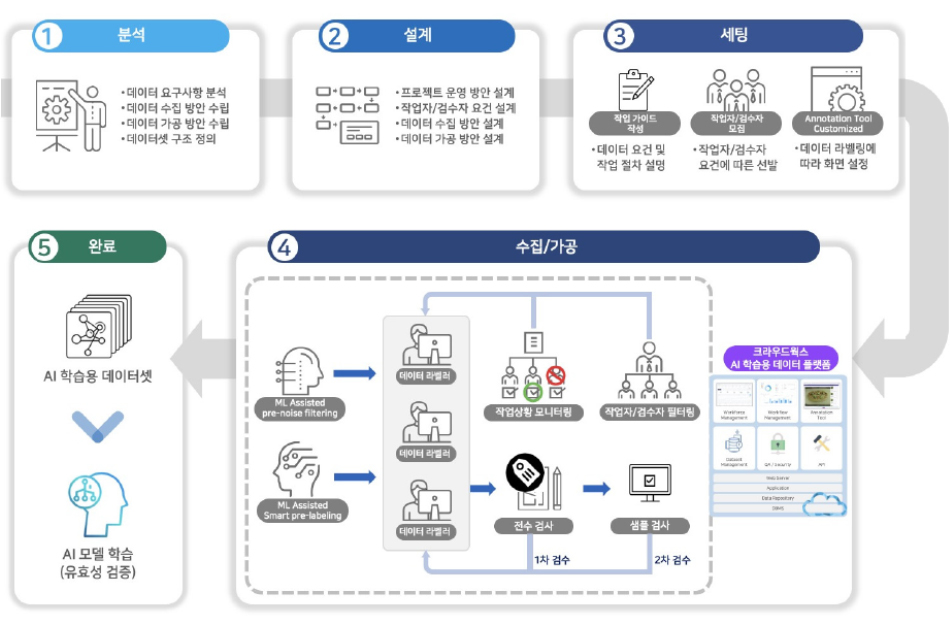
<자료> 박영진, “인공지능 학습용 데이터 플랫폼 연구”, 한국통신학회지, 정보와통신, 39(11), 2022, 23-29. 재구성
[그림 5] 데이터 라벨링 워크플로
- 세팅: 데이터 수집, 정제, 가공 등 모든 작업에 필요한 작업 기준 및 작업 방법을 설명하는 작업 가이드를 준비하고, 작업자를 모집/선발하고 작업 도구(annotation tool)를 설정한다.
- 수집/가공: 데이터 수집/가공 작업을 진행하면서 작업 전체에 대한 진행 상황 및 작업자 개인별 작업 상황을 모니터링하면서 작업을 분배하고 필요한 경우 추가 인력을 투입한다.
데이터 어노테이션은 다양한 유형의 데이터에서 특정 개체, 영역 또는 특성을 식별하고 레이블링하는 작업으로서 대부분 사람에 의한 수작업을 통해서 수행되며 이를 위해 데이터 어노테이션 도구를 사용한다.
- 미지 어노테이션: 이미지에서 객체 검출(object detection), 분할(segmentation), 포즈 추정(pose estimation) 등을 하기 위해서 이미지에 포함된 객체, 물체, 얼굴, 텍스 트 등을 식별하고 라벨링한다.
- 비디오 어노테이션: 비디오에서 객체 추적(object tracking), 행동 인식(action recognition), 이벤트 감지(event detection) 등을 위해서 비디오에 포함된 객체 또는 행동을 식별하고 라벨링한다.
- 음성 어노테이션: 음성 인식(speech recognition), 화자 분리(speaker separation), 감정 분석(emotion analysis) 등을 위해서 음성 데이터에서 단어, 문장, 화자, 감정 등을 식별하고 라벨링한다.
- 텍스트 어노테이션: 텍스트 데이터에서 개체명 인식(named entity recognition), 감정 분석(emotion analysis), 문서 분류(document classification) 등을 위해서 단어, 문장, 문서, 개체명(named entity), 감정 등을 식별하고 라벨링한다.
어노테이션 도구는 한번 만들어서 계속 사용되는 것이 아니라 라벨링 방식이나 학습용 데이터셋에 따라서 계속 변경될 수 있어서 지속적으로 새로운 어노테이션 방식에 맞춰서 추가 개발이 이루어져야 한다.
4. 데이터셋 관리머신러닝 학습용 데이터셋 관리는 모델을 학습시키는데 필수적인 역할을 하는 학습용 데이터셋을 적절하게 관리하고 저장하는 것이 모델의 성능과 안정성을 보장하는 데 중요하다.
- 데이터셋 저장: 일반적으로 클라우드 기반 스토리지(예; Amazon S3, Google Cloud Storage 등)와 로컬 스토리지(예; 하드 드라이브, NAS 등)에 저장하며 구조화된 데이터의 경우 데이터베이스에 저장하여 관리할 수 있다.
- 데이터셋 구조화: 학습용 데이터셋을 체계적으로 구성하여 관리할 수 있도록 카테고리나 데이터 유형에 따라 폴더와 파일로 구분하여 관리한다.
- 데이터 백업 및 복구: 정기적으로 데이터를 백업하여 데이터 손실을 예방해야 한다. 클라우드 스토리지나 NAS 장비에서 제공하는 자동 백업 기능을 활용할 수 있고, 별도의 외부 저장장치에 사본을 만들어 보관하여 데이터 복구가 가능하도록 한다.
- 데이터 보안: 인공지능 학습용 데이터셋에 오류가 포함되면 이를 기반으로 학습하는 머신러닝 모델에 직접적인 영향을 줄 수 있으므로 적절한 암호화 및 보안 조치를 적용하여 데이터의 무결성과 기밀성을 확보하고 데이터셋에 대한 접근 권한에 대한 세분화된 관리를 통해 학습용 데이터에 대한 무단 접근을 방지해야 한다.
AI 데이터 플랫폼은 [표 1]과 같이 적용 방식, 상용 여부, 인력 관리 방식 등의 기준에 따라 다음과 같이 분류할 수 있다.
[표 1] AI 데이터 플랫폼 종류
| 갯수 | 구분 | 내역 |
|---|---|---|
| Deployment Model |
On-Premise | 데이터의 보안 등의 이유로 데이터 외부 유출이 제약이 있는 경우 또는, AI 모델이나 응용 시나리오가 일반적이지 않고 특수한 상황일 때 데이터 라벨링 시스템을 별도로 구축하여 특정 목적에 최적화된 데이터 라벨링을 할 수 있도록 데이터 플랫폼을 제공하는 방식이다. |
| SaaS | 가장 일반적인 인공지능 학습용 데이터 플랫폼 형태로서 클라우드(Cloud) 상에 데이터 라벨링 서비스를 구축하여 제공하는 형식으로 데이터 라벨링 관련 주요 기능을 제공하고 있으며, 데이터 수집/정제부터 가공/검수 및 AI 모델 적용까지 일괄 제공되며, 고객의 요구에 맞춰 필요한 서비스만 사용할 수 있도록 제공하고 있다 | |
| Buy or Build | Commercial | 구글, AWS, MS, IBM, SuperAnnotate, V7, Appen, Labelbox, Hive Data, 크라우드웍스, 에이모, 테스트웍스 등 국내외 중소기업부터 대기업까지 다양한 공급 업체가 있으며, 데이터 라벨링 관련 서비스 를 제공하고 있다. |
| Open source |
CVAT
|
|
| In-house | AI 모델이나 응용 시나리오에 최적화된 데이터 라벨링 플랫폼을 직접 개발하는 방식으로 예산과 시간을 고려하여 데이터 라벨링에 필요한 요구사항을 반영하여 데이터 라벨링 플랫폼을 개발한다. |
<자료> 박영진, “인공지능 학습용 데이터 플랫폼 연구”, 한국통신학회지, 정보와통신, 39(11), 2022, 23-29. 재구성
Ⅴ. 결론
머신러닝 모델 성능을 위해서는 정확하고 일관성 있는 고품질의 인공지능 학습용 데이터가 필수적이다. 본 고에서는 일관성과 품질을 유지하면서 머신러닝 모델 학습용 데이터를 수집/정제/가공할 수 있는 AI 데이터 플랫폼을 데이터 중심 AI 관점에서 소개하였다. 데이터가 인공지능 알고리즘의 성능을 결정하는 핵심 요소이기 때문에 AI 데이터 플랫폼은 데이터 라벨러(workforce) 관리, 데이터 작업 프로세스(workflow) 관리, 어노테이션 도구(annotation tool), 데이터셋 관리 등의 기능을 제공해야 한다. AI 데이터 플랫폼을 통해 머신러닝을 위한 일관성 있고 정확한 고품질 라벨링 데이터를 확보할 수 있는 데이터 파이프라인을 구축하고 머신러닝 모델의 성능을 유지하고 개선 및 보완할 수 있는 체계로 활용할 수 있다. 또한, 많은 기업과 기관에서 인공지능을 도입하여 다양한 업무와 서비스 등에 적용이 확대될 것으로 예상된다. 이때 인공지능 학습용 데이터를 중앙 집중적으로 관리하여 데이터의 품질과 일관성을 보장할 수 있도록 AI 데이터 플랫폼이 필수적인 요소로 자리 잡을 것이다. 또한, 인공지능을 도입하고 적용하고 활용하면서 머신러닝 모델에 대한 전문성과 경험은 축적되고 있지만, 데이터에 대한 전문성과 경험은 축적되지 못하고 있는데, AI 데이터 플랫폼을 구축하고 운영하면서 인공지능에 있어서 또 다른 경쟁력인 학습용 데이터와 관련된 역량을 확보하고 축적할 수 있을 것으로 기대된다.
[1] 박대륜, 안중민, 장준혁, 유원진, 김우열, 배영권, 유인환, “머신러닝 플랫폼을 활용한 소프트웨어 교수-학습 모형 개발”, 정보교육학회논문지, 제24권 제1호, 2020, pp.49-57.
[2] Shinta Nakayama, Michiaki Ariga, Takashi Nishibayashi, Machine Learning at Work, O’Reilly, 2018.
[3] Chew, R., Wenger, M., Kery, C., Nance, J., Richards, K., Hadley, E., & Baumgartner, P., SMART: an open source data labeling platform for supervised learning, The Journal of Machine Learning Research, 20(1), 2019, 2999-3003.
[4] Sculley, D., Holt, G., Golovin, D., Davydov, E., Phillips, T., Ebner, D., Chaudhary, V. & Young, M., “Machine learning: The high interest credit card of technical debt”, 2014.
[5] 김지훈, 이정호, 김태윤, & 김재현, “골프 스윙 자세교정을 위한 Faster R-CNN 기반 머리 인식 모델 설계”, 한국통신학회 학술대회논문집, 2020, pp.509-510.
[6] Andrew Burt and Patrick Hall, What to Do When AI Fails, O’reilly Radar, 2020.
[7] Brown, S. (2022). Why it’s time for'data-centric artificial intelligence'. MIT Management, 8(19), 2022.
[8] Y. Roh, G. Heo, and S. E. Whang, “A survey on data collection for machine learning: a big data-ai integration perspective”, IEEE Transactions on Knowledge and Data Engineering, 2019.
[9] Y. Daniel, F., Kucherbaev, P., Cappiello, C., Benatallah, B., & Allahbakhsh, M., “Quality control in crowdsourcing: A survey of quality attributes, assessment techniques and assurance actions”, ACM Computing Surveys(CSUR), 51(1), 2018, pp.1-40.
* 본 자료는 공공누리 제2유형 이용조건에 따라 정보통신기획평가원의 자료를 활용하여 제작되었습니다.